Looking for current scores? The live ARC-AGI-2 leaderboard tracks every model's latest result — this post explains the benchmark itself.
ARC-AGI-2 Explained: The Hardest Public Reasoning Benchmark
ARC-AGI-2 is a benchmark of visual grid puzzles that test fluid intelligence: the ability to identify a novel pattern from a few examples and apply it to a new input. Unlike knowledge benchmarks like MMLU or GPQA, ARC-AGI-2 cannot be solved by memorization. Average humans score 66% on it. The grand prize threshold for the public ARC Prize is greater than 85%. As of April 2026, top frontier models reach 75–85, with GPT-5.5 the highest in our data at 85.
TL;DR
- What it tests: Fluid intelligence, meaning pattern induction from few examples on visual grid puzzles.
- Average human performance: 66% (per the ARC-AGI-2 GitHub repository's test sample).
- Panel completion rate: 100%; every task was solved by at least 2 humans in 2 attempts or less in the calibration study.
- Grand prize threshold: greater than 85%, with a $700,000 prize at stake (ARC Prize 2026).
- Top score in our data (April 2026): GPT-5.5 at 85.
- Why it matters: Cannot be solved by memorization, doesn't compress at the top, and remains the hardest public reasoning benchmark in 2026.
Jump to the current leaderboard for the full ranking, or read on for what ARC-AGI-2 actually measures.
What ARC-AGI-2 actually is
Each ARC-AGI-2 task is a small visual puzzle. The model is shown a handful of input/output grid pairs (typically two to four) and has to figure out the transformation rule that maps each input to its output. Then it gets a new test input and has to produce the correct output grid. Cells in every grid are integers from 0 to 9, mapped to a fixed ten-color palette. The palette is decorative; the difficulty lives in the structure.
The format is deliberately few-shot. Two or three examples is rarely enough to disambiguate a rule by pattern matching alone. To get the right output the model has to generate hypotheses, check each one against the demonstration pairs, refine when a hypothesis fails, and commit to the rule that survives every example. The rules are not given. They are not drawn from a published taxonomy. Each puzzle is its own one-off problem.
The choice of visual grids is doing real work in the benchmark design. Knowledge benchmarks like MMLU and GPQA Diamond reward the ability to retrieve facts the model has seen many times during training. ARC-AGI-2 deliberately avoids that. The puzzles are visual and combinatorial precisely because text-based reasoning probes risk leaking into pre-training data. A grid transformation rule that has never appeared in a textbook gives the benchmark room to discriminate genuine pattern induction from memorized solutions.
The capability the benchmark targets has a name in psychology: fluid intelligence. Raymond Cattell's distinction separates fluid intelligence (the on-the-fly ability to reason about novel problems and identify patterns under uncertainty) from crystallized intelligence, the accumulated body of facts and procedures a person has internalized over time. Most LLM benchmarks reward crystallized intelligence: the model that has seen more text wins. Fluid intelligence is harder to fake, because pre-training gets you no closer to a problem you've never encountered. ARC-AGI-2 is one of the few public benchmarks engineered specifically to isolate that capability.
 Easy-tier ARC-AGI-2 puzzle (
Easy-tier ARC-AGI-2 puzzle (00576224). Each cell holds an integer 0–9 mapped to a fixed color palette. The model sees the demonstration pairs and must output the correct grid for the test input. Source: ARC-AGI-2 public training set, ARC Prize Foundation, Apache-2.0 license.
The rule for this puzzle: tile the 2x2 input three times across the row, then arrange three vertical bands of two rows each: original, vertically flipped, original. Two demonstration pairs disambiguate it cleanly. A model that gets the horizontal tiling but misses the flip will produce a 6x6 output that's wrong on rows 3 and 4. The benchmark does not give partial credit for "almost right" outputs. Every cell must match.
ARC-AGI-1 vs ARC-AGI-2: what changed
The original Abstraction and Reasoning Corpus, ARC-AGI-1, was launched in 2019 by François Chollet as a deliberate counterweight to benchmarks that rewarded memorization. For five years it was the bar that frontier AI couldn't cross. Pure language models scored in the single digits. Domain-specific systems crept up but no model paired generality with a meaningful score. The benchmark's reputation rested on that gap. Then OpenAI's o3 reasoning system landed on ARC-AGI-1's high-compute regime in late 2024 and the bar moved overnight. The benchmark Chollet had used to argue that fluid intelligence was the missing piece was suddenly being approached.
ARC-AGI-2 was released on March 24, 2025, with the explicit goal of reopening the gap. The redesign tightened the benchmark in three ways. First, the team removed brute-force solvable tasks, puzzles where a search-heavy approach without genuine reasoning could find the answer. Second, they ran controlled human testing for calibration: hundreds of human participants worked through the eval set under timed conditions, and tasks were retained only if at least two humans solved them in two attempts or less. Every task in the final eval set was solved by humans 100% of the time at the panel level, with average individual performance landing at 66%. Third, the new tasks were designed to target specific weaknesses observed in 2024-era reasoning systems: symbolic interpretation, compositional reasoning across multiple subrules, and contextual rules that depend on the input rather than a fixed transformation.
The result was a benchmark that re-collapsed frontier scores. At launch in March 2025, OpenAI's o3-preview-low scored 4% on ARC-AGI-2. The same model had cleared 75.7% on ARC-AGI-1. Pure LLMs without explicit reasoning scaffolding scored 0%. The gap to the 85% grand prize threshold was wide open again. ARC Prize Foundation has since publicly committed to ARC-AGI-3 as a successor track focused on interactive agentic reasoning; the 2026 ARC Prize competition runs both tracks in parallel and 2026 is the announced final year of the ARC-AGI-2 track.
How the benchmark works
Four moving parts shape what an ARC-AGI-2 score actually means. Puzzle structure, scoring rules, eval-set splits, and the submission process each contribute to why the benchmark is hard to game.
Puzzle structure
Each task has two to four demonstration pairs and one to two test inputs. Grid sizes are typically small to medium; most fall in the 3x3 to 30x30 range, though some puzzles change grid dimensions between input and output. The ten-color palette is fixed and doesn't carry semantic weight: color 4 isn't conceptually different from color 7. What matters is which cells share a color, which form connected regions, which sit in symmetric positions. The transformation rules themselves are never stated. They have to be inferred from the demonstration pairs alone, then applied cleanly to the test input.
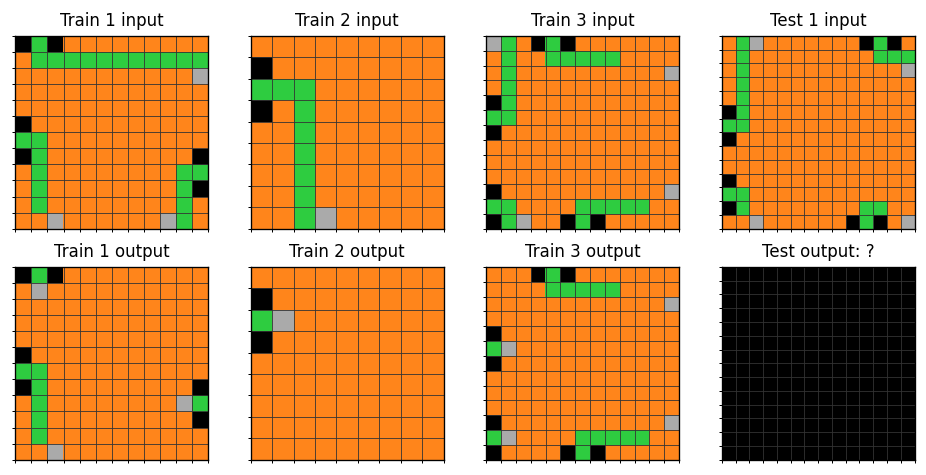 Medium-tier ARC-AGI-2 puzzle (
Medium-tier ARC-AGI-2 puzzle (182e5d0f). Three demonstration pairs of differing grid sizes (9x9, 12x12, 13x13). Source: ARC-AGI-2 public training set, ARC Prize Foundation, Apache-2.0 license.
This puzzle is harder than the easy example because the demonstration pairs use different grid sizes. The model can't memorize a per-size mapping; it has to learn a size-independent rule and prove it generalizes by applying it to a 14x14 test input. That single design choice, varying input dimensions across pairs, is one of the cleanest ways the benchmark forces genuine abstraction.
Scoring
ARC-AGI-2 uses pass@2: the model gets two attempts per task, and the first correct answer counts. There is no partial credit. Every cell of the output grid must match the reference exactly. A model that gets the rule almost right but is off-by-one on grid dimensions, or correct on rule but wrong on a single cell, scores zero on that task. The reported benchmark score is the percentage of tasks where one of the two attempts produced an exact match: a strict, binary measurement repeated across the eval set. There is no smoothing, no rubric judgement, no LLM-as-judge intermediary.
Eval set splits
The benchmark is structured as three nested datasets. The public training set lives in the official GitHub repository at github.com/arcprize/ARC-AGI-2/tree/main/data/training under an Apache-2.0 license: 1,000 tasks freely downloadable for training, debugging, and public discussion. The puzzles embedded in this post come from that set. The semi-private eval set is held by ARC Prize Foundation and used to populate the public leaderboard; teams can submit and get a score back, but the underlying puzzles aren't released. The fully private holdout is reserved for the formal Kaggle competition. Submissions there can't be debugged against the data; solutions ship blind. The split exists to prevent training-set contamination from polluting the headline numbers; if a competition entry could memorize the eval set, the leaderboard would be meaningless.
Submission process
ARC-AGI-2 scores reach the public in two ways. First, AI labs self-report scores in launch announcements: Anthropic, Google, OpenAI, and xAI all publish ARC-AGI-2 numbers when they ship new frontier models. Second, the formal Kaggle competition (ARC Prize 2026 carries $700,000 in grand prize money for ARC-AGI-2) runs against the private holdout under strict efficiency limits. Our leaderboard tracks the lab self-reports. When a lab claims a score without releasing methodology details, treat the number as a self-report rather than an audited leaderboard rank. The Kaggle results are the closest thing the benchmark has to an audited measurement.
The grand prize and human baselines
Two human baseline numbers matter here, and they measure different things. The ARC-AGI-2 calibration study, run during the 2025 redesign, recruited hundreds of human participants and put each task through a controlled solving session. The result reported in the official launch announcement: every task in the eval set was solved by at least two humans in two attempts or less. That's a 100% panel-completion rate, the bar that any individual task must clear to enter the eval set. Average individual performance, reported in the GitHub repository's documentation, was 66% on the test sample. That's the figure to anchor on when comparing AI to human performance: not "AI vs the best human" or "AI vs the panel," but AI vs the average individual sitting down with a fresh set of puzzles.
The grand prize threshold is set higher than human average performance. A team has to score greater than 85% on the private holdout, within Kaggle's compute and runtime efficiency limits, to claim the ARC Prize 2026 grand prize of $700,000. That bar wasn't reached in either the 2024 or the 2025 competition years. 2026 is the announced final year of the ARC-AGI-2 track and the grand prize is guaranteed to be paid to the highest-scoring team regardless of whether the 85% line is crossed.
A 66% average human baseline and an 85% prize threshold are not the same target. The gap between them isn't a measurement quirk; it's deliberate. The grand prize is meant to mark not just "matches an average human" but "decisively beats them under engineering constraints." A model sitting at 75% has surpassed average human performance on a benchmark designed to be hard; that's not failure. The remaining gap to 85% is to a separate, harder target: efficient performance on the private holdout under competition rules.
This distinction matters when reading headlines. "AI hasn't matched humans on ARC-AGI-2" was true through most of 2025, when frontier models scored in the single digits. As of April 2026 it is not. Top frontier models exceed 66% by a wide margin. They have not crossed 85%, but that's a target above the human average, not at it.
Current leaderboard
Pulled from our tracked benchmark data, the top ten models on ARC-AGI-2 as of April 2026:
| # | Model | Reasoning | ARC-AGI-2 |
|---|---|---|---|
| 1 | GPT-5.5 | Reasoning | 85 |
| 2 | GPT-5.4 Pro | Reasoning | 83.3 |
| 3 | Gemini 3.1 Pro | Non-Reasoning | 77.1 |
| 4 | Claude Opus 4.7 (Adaptive) | Reasoning | 75.8 |
| 5 | GPT-5.4 | Reasoning | 73.3 |
| 6 | Claude Opus 4.6 | Non-Reasoning | 68.8 |
| 7 | Claude Sonnet 4.6 | Non-Reasoning | 59 |
| 8 | GPT-5.2 Pro | Reasoning | 54.2 |
| 9 | Grok 4.20 | Reasoning | 53.3 |
| 10 | GPT-5.2 | Reasoning | 52.9 |
Full rankings: ARC-AGI-2 leaderboard
The spread is the story. Top model is at 85, tenth place is at 52.9, and there's another 17 models below the cut with scores running down to single digits: DeepSeek V3.2 at 4, o3 at 3, DeepSeek-R1 at 1.3. ARC-AGI-2 doesn't compress at the top the way GPQA Diamond and MMLU do, and it doesn't compress at the bottom either. That's rare for a benchmark with a 66% human average. Most benchmarks that humans find moderately hard end up either too easy for frontier models (everything piles up at 95+) or too hard (everything piles up below 30). ARC-AGI-2 has genuine separation across the entire frontier of reasoning model capability.
Reasoning configurations dominate the top of the leaderboard. Of the top five, four are explicit-reasoning models: GPT-5.5, GPT-5.4 Pro, Claude Opus 4.7 in Adaptive mode, GPT-5.4. The single non-reasoning standout is Gemini 3.1 Pro at 77.1, slotting between the two GPT Pro variants. Below the top five the picture is less clean: Claude Opus 4.6 (non-reasoning) at 68.8 sits ahead of GPT-5.2 Pro (reasoning) at 54.2, demonstrating that absolute model capability still matters more than the reasoning toggle alone.
GPT-5.5's 85 sits exactly at the published grand prize threshold. That alignment is suggestive but not decisive: our leaderboard tracks lab self-reports, not the audited Kaggle private-holdout score that the ARC Prize requires for an official grand prize claim. Whether GPT-5.5's reported 85 corresponds to a Kaggle submission that cleared the efficiency limits is not stated in the data we track. Treat the leaderboard score as the public-facing number it is (a useful comparison signal) and the official ARC Prize grand prize as a separate, formally adjudicated event.
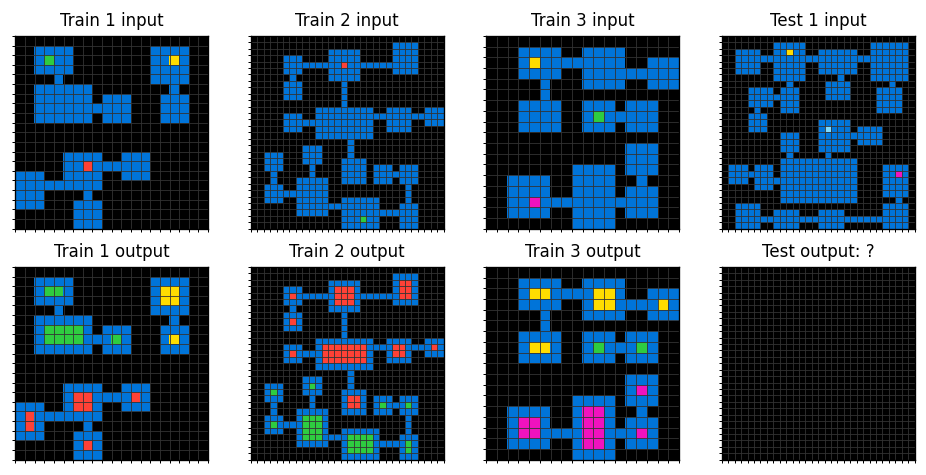 Hard-tier ARC-AGI-2 puzzle (
Hard-tier ARC-AGI-2 puzzle (09c534e7). Three demonstration pairs of differing large-grid sizes (18x18, 20x20, 30x30); the test input is 30x30. Even top frontier models may fail puzzles at this difficulty. Source: ARC-AGI-2 public training set, ARC Prize Foundation, Apache-2.0 license.
This puzzle is hard because the demonstration pairs are large and the rule has to hold across multiple objects in a sparse grid. The model has to identify the relevant objects, infer how each one transforms, and prove the rule generalizes by applying it correctly to a 30x30 test input. The combinatorial space of possible rules at this grid size is vast, and the puzzle gives only three examples to disambiguate. This is the territory where the reasoning-vs-non-reasoning gap on the leaderboard widens, and where even GPT-5.5 doesn't get every puzzle right.
Reasoning vs non-reasoning models on ARC-AGI-2
The leaderboard tells a clean story: ARC-AGI-2 favors reasoning models. Of the top five, four use explicit reasoning configurations: GPT-5.5, GPT-5.4 Pro, Claude Opus 4.7 in Adaptive mode, and GPT-5.4. The numbers cluster tightly: 85, 83.3, 75.8, 73.3. The top five non-reasoning model (Claude Opus 4.6) sits at 68.8, several points below the bottom of that reasoning cluster.
Gemini 3.1 Pro is the standout exception, scoring 77.1 in non-reasoning mode and slotting between the two GPT Pro variants in third place overall. That's a meaningful data point. It means the reasoning toggle isn't strictly necessary for top-tier ARC-AGI-2 performance; a sufficiently capable base model can compete. But Gemini 3.1 Pro is the only model in the top five demonstrating that, and the rest of the non-reasoning field falls off quickly: Claude Opus 4.6 at 68.8, Claude Sonnet 4.6 at 59, Claude Opus 4.5 at 37.6. The trend supports the toggle, even if it doesn't require it.
The mechanism is intuitive. ARC puzzles benefit from iterative hypothesis-testing: generate a candidate rule, check it against the first demonstration pair, refine when it fails to explain the second, and commit to a rule that survives every example. That loop is exactly what chain-of-thought scaffolding enables. A model that can spend tokens trying rules and rejecting them outperforms a model forced to commit to its first guess. The cost is that reasoning models burn output tokens during inference. Solving ARC-style problems with thinking enabled means longer latency and higher per-task spend. The pricing implications matter at scale; the April 2026 flagship comparison walks through what this looks like on the bill.
What ARC-AGI-2 actually predicts about model capability
ARC-AGI-2 measures one specific facet of reasoning: pattern induction from few examples on a tightly-defined problem class. It is not a general intelligence test, despite the name. The "AGI" in ARC-AGI is making a bet, not a claim. François Chollet's argument is that fluid intelligence is the missing piece for genuinely general AI; the benchmark is built to isolate that capability and watch it move. A high score is evidence of strong fluid intelligence on the grid-puzzle problem class. It is not direct evidence of high performance on every reasoning task you might care about, and the post-2024 scoring leaders are still narrow systems by any reasonable definition of generality.
What ARC-AGI-2 does correlate with in practice: agentic task performance on novel domains, where the model has to adapt to environment dynamics it hasn't been trained on. Coding tasks where requirements are ambiguous and the model needs to infer intent from a few examples. Reasoning tasks where the answer can't be retrieved from memorization because the problem has never been published. These all share the structural property ARC-AGI-2 was built for: solving an unfamiliar problem from limited evidence.
What it does not predict: knowledge recall, where MMLU and GPQA are the right probes. Instruction-following fidelity, where IFEval is the standard. Conversational quality, which Arena Elo measures. Multilingual reasoning, where MGSM and MMLU-ProX cover ground ARC-AGI-2 doesn't. A model with a 75 on ARC-AGI-2 and a 60 on HLE is fluid-intelligence strong but knowledge-thin. A model with the inverse profile is the opposite. Those are different capability portraits. The benchmark suite has to span them; no single test does.
The reason "AGI" sits in the benchmark's name despite the narrow task scope traces back to Chollet's 2019 paper introducing the original ARC. His argument: crystallized intelligence (the ability to retrieve and apply learned procedures) is necessary but not sufficient for general intelligence. Fluid intelligence, the ability to handle problems outside the training distribution, is what closes the gap. ARC was named for that bet. Whether the bet is right is an open empirical question that the benchmark is designed to help answer.
ARC-AGI-2 vs other reasoning benchmarks
Most reasoning benchmarks share the same structural problem: they reward models that have memorized similar problems. ARC-AGI-2 is engineered around that failure mode. Comparing it to the rest of the reasoning evaluation suite shows where the differences actually live.
| Benchmark | What it really tests | Format | Top frontier scores |
|---|---|---|---|
| ARC-AGI-2 | Fluid intelligence — pattern induction from few examples | Visual grid puzzles, pass@2 | 75–85 |
| GPQA Diamond | PhD-level science domain knowledge | 198 multiple-choice questions | 95–97 |
| HLE (Humanity's Last Exam) | Frontier expert-level questions across many domains | Open-ended Q&A | 30–55 |
| MuSR | Multi-step soft reasoning across narratives | Murder mysteries, team allocation, object placement | 80–95 |
| LongBench v2 | Multi-document reasoning over long context | QA + reasoning over 8K–2M token inputs | varies by length |
GPQA Diamond is the closest peer in spirit: a benchmark that is "Google-proof" in that no internet search will reveal the answer. But GPQA tests deep crystallized knowledge in three science domains. A model that knows molecular biology, particle physics, and computational chemistry at PhD level scores 95+. ARC-AGI-2 tests something orthogonal: the ability to invent procedures on the fly from minimal examples. A model can be brilliant at GPQA and mediocre on ARC-AGI-2, or vice versa.
HLE (Humanity's Last Exam) targets the long tail of expert-level questions across many academic disciplines. It punishes shallow knowledge in any one field by sampling broadly. The score range is wide because the questions span everything from rare-language linguistics to obscure physics, and most models fail half or more. HLE rewards encyclopedic crystallized intelligence; ARC-AGI-2 deliberately removes the option to use any.
MuSR sits in a different niche: narrative-driven reasoning where the model has to track entities, motivations, and constraints through a multi-step problem. Top frontier models clear 90+ on it. The skill MuSR rewards is closer to what a careful reader does on a complex text; ARC-AGI-2 rewards what a careful pattern-finder does on a sparse visual puzzle. Different cognitive surfaces, both real.
LongBench v2 tests reasoning over very long inputs; the question isn't "can you solve this puzzle" but "can you keep track of what you read across hundreds of thousands of tokens." It's a context-window capability test, not a fluid-intelligence test. Models that ace ARC-AGI-2 do not necessarily ace LongBench v2 and vice versa.
The picture across the suite: ARC-AGI-2 sits in a category by itself among public reasoning benchmarks. Most others test domain knowledge or chained reasoning over a fixed task type. ARC-AGI-2 tests the meta-skill of inventing a procedure from a handful of examples, and that's why it discriminates so widely across the leaderboard. The full reasoning category breakdown lives at /reasoning, and the April 2026 flagship comparison covers how the top reasoning models stack up across multiple benchmark surfaces.
Further reading
Other benchmark explainers and reasoning resources on benchlm.ai:
- ARC-AGI-2 leaderboard: live model rankings, updated as new scores publish.
- Best reasoning models: recommended picks for reasoning workloads.
- Reasoning category page: full reasoning ranking across ARC-AGI-2, LongBench v2, MRCRv2, and MuSR.
- GPQA Diamond explained: sibling explainer for the PhD-level science benchmark.
- DeepSeek V4 Pro vs Claude Opus 4.7 vs GPT-5.5: how the April 2026 flagships compare on reasoning benchmarks.
- State of LLM benchmarks 2026: broader survey of which benchmarks still discriminate.
External:
- ARC Prize Foundation: official site, paper, prize details.
- ARC-AGI-2 launch announcement: primary source for human baselines and prize structure.
- ARC-AGI-2 public training set: Apache-2.0 puzzle JSON files (1,000 tasks).
For a head-to-head leaderboard view across all reasoning benchmarks, the model explorer tracks every benchmark referenced in this post as new scores publish.
Reader questions
Frequently asked questions
01What is ARC-AGI-2?
ARC-AGI-2 is the second-generation Abstraction and Reasoning Corpus benchmark from François Chollet and the ARC Prize Foundation. It tests fluid intelligence through visual grid puzzles where the model must infer a transformation rule from a handful of input/output examples and apply it to a new test input. Unlike MMLU or GPQA, ARC-AGI-2 cannot be solved by memorization; every puzzle is novel.
02How is ARC-AGI-2 different from ARC-AGI-1?
ARC-AGI-1 launched in 2019 and was eventually cleared by 2024-era reasoning systems. ARC-AGI-2 released March 24, 2025 to reopen the gap. It removed brute-force solvable puzzles, calibrated tasks with controlled human testing (panel completion 100%, individual average 66%), and targeted reasoning-system weaknesses in symbolic interpretation, compositional reasoning, and contextual rules. Models scoring 75%+ on ARC-AGI-1 fell to single digits on ARC-AGI-2 at launch.
03What's the highest ARC-AGI-2 score?
As of April 2026, the highest ARC-AGI-2 score in BenchLM's tracked data is GPT-5.5 at 85, sitting at the published grand prize threshold. GPT-5.4 Pro follows at 83.3, Gemini 3.1 Pro at 77.1, and Claude Opus 4.7 Adaptive at 75.8. BenchLM tracks lab self-reports rather than audited Kaggle competition results.
04Has any AI won the ARC-AGI-2 grand prize?
No. The ARC Prize 2026 grand prize is $700,000, awarded to the first team scoring greater than 85% on the private holdout within Kaggle's efficiency limits. The threshold was not reached in either 2024 or 2025. Lab self-reports at or above 85 are not the same as an audited Kaggle submission. 2026 is the final year of the ARC-AGI-2 track, and the grand prize will go to the highest-scoring team regardless of whether 85% is crossed.
05Can I try ARC-AGI-2 puzzles myself?
Yes. The public training set is on GitHub at github.com/arcprize/ARC-AGI-2 under Apache-2.0 — 1,000 puzzles you can download as JSON, render, and solve by hand. The semi-private eval set and the fully private holdout are not publicly released; those are reserved for the official ARC Prize evaluation pipeline. The puzzles embedded in this post come from the public training set.
Source ledger
External sources linked in this article
- 01ARC Prize Foundationarcprize.org
- 02ARC-AGI-2 launch announcementarcprize.org
- 03ARC-AGI-2 public training setgithub.com
Share or save